Spring Batch
05. Backup Batch - 1
- -
이번 포스트에서는 간단한 Backup batch를 만들어보면서 Step을 구성해보자.
기본 작업
배치 시나리오 및 Mapper 설정
이번에 처리해볼 배치는 매월 source인 Sakila에 있는 대량의 결재 정보를 target인 quietjun에 백업하는 작업이다.
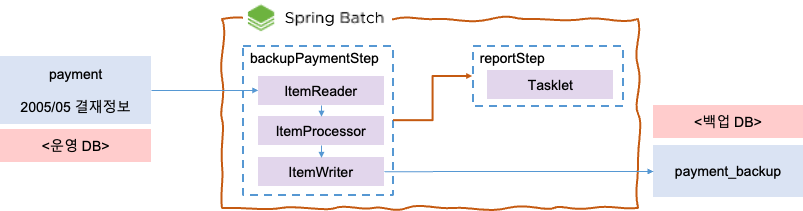
실제 비지니스에서도 아주 오래된 결재 내역을 운영 DB에서 계속 가져갈 경우 부하가 증가할 수 있기 때문에 최근의 이력만을 가져가는게 유리한데 그렇다고 무작정 지워버리면 법적으로 문제되기 때문에 주기적인 백업이 필요한 상황이다.
현재 sakila database에 쌓인 결재 내역은 다음의 쿼리로 확인할 수 있다.
select date_format(payment_date, '%Y-%m') as 'yearMonth' , count(payment_id) as '결재건수'
from payment
group by yearMonth;
backup table 및 DTO 작성
sakila의 payment를 참조하여 backup_db에 backup 테이블을 구성한다.
CREATE TABLE payment_backup (
payment_id SMALLINT primary key,
customer_id SMALLINT UNSIGNED NOT NULL,
staff_id TINYINT UNSIGNED NOT NULL,
rental_id INT DEFAULT NULL,
amount DECIMAL(5,2) NOT NULL,
payment_date DATETIME NOT NULL,
last_update TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
backup_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
payment_ym VARCHAR(7) NOT NULL,
INDEX idx_year_month (payment_ym),
INDEX idx_customer (customer_id),
INDEX idx_payment_date (payment_date)
);그리고 위 테이블을 참조해서 DTO를 작성해보자. 이 DTO는 sakila와 backup에서 동일하게 사용한다.
@Data
public class Payment {
private Integer paymentId;
private Integer customerId;
private Integer staffId;
private Integer rentalId;
private BigDecimal amount; // 실수계산 정확도를 위해 double보다 BigDecimal 권장
private LocalDateTime paymentDate;
private LocalDateTime lastUpdate;
private String paymentYm; // YYYYMM 형태로 저장
private LocalDateTime backUpDate;
}
데이터 조회를 위한 mapper 구성
<!--sakila-mapper.xml-->
<select id="selectMonthlyPayments" resultMap="paymentBasic">
SELECT
payment_id, customer_id, staff_id, rental_id, amount,
payment_date, last_update
FROM payment
WHERE DATE_FORMAT(payment_date, '%Y-%m') = #{yearMonth}
ORDER BY payment_id ASC
</select>
<resultMap type="payment" id="paymentBasic" autoMapping="true">
<id property="paymentId" column="payment_id" />
<result property="customerId" column="customer_id" />
<result property="staffId" column="staff_id" />
<result property="rentalId" column="rental_id" />
<result property="paymentDate" column="payment_date" />
<result property="lastUpdate" column="last_update" />
<result property="paymentYm" column="payment_ym" />
<result property="backupDate" column="backup_date" />
</resultMap>public interface SakilaMpper {
public List<Payment> selectMonthlyPayments(String paymentDate);
}
데이터 저장을 위한 mapper 구성
<insert id="insertPaymentBackup" parameterType="Payment">
INSERT INTO payment_backup (payment_id, customer_id, staff_id, rental_id, amount,
payment_date, last_update, backup_date, payment_ym)
VALUES (#{paymentId}, #{customerId}, #{staffId}, #{rentalId},
#{amount}, #{paymentDate}, #{lastUpdate}, #{backupDate}, #{paymentYm})
</insert>public interface QuietjunMapper {
public int insertPaymentBackup(Payment payment);
}
ItemReader
기본
ItemReader는 배치 작업에서 입력 소스에서 데이터를 가져올 수 있는 기본 interface이고 read() 메서드를 통해 대상을 조회할 수 있다.
@FunctionalInterface
public interface ItemReader<T> {
@Nullable T read() throws Exception;
}ItemReader는 다양한 입력 소스를 지원한다.
- Flat File: CSV 같은 일반 텍스트 파일에서 한 줄 씩 데이터를 읽어와 고정된 위치, 특정 문자 기준으로 데이터를 처리한다. 대표적 구현체로 FlatFileItemReader가 사용된다.
- XML: XML 파일에서 데이터를 읽어오는데 파싱이나 매핑 같은 기술에 구애받지 않고 유연하게 처리할 수 있다. 대표적인 구현체로 StaxEventItemReader 를 들 수 있다.
- Database: SQL을 활용하는 ItemReader들로 사용하는 persistence framework에 따라 다양하게 제공된다.
- JDBC 기반: JdbcCursorItemReader, JdbcPagingItemReader
- JPA 기반: JpaCursorItemReader, JpaPagingItemReader
- MyBatis 기반: MyBatisCursorItemReader, MyBatisPagingItemReader
이 외에도 다양한 ItemReader가 제공되고 있다.
일반적으로 Cursor 기반과 Paging 기반은 다음의 차이를 갖는다.
| 기준 | Mybatis Cursor 기반 (MybatisCursorItemReader) | Mybatis Paging 기반 (MybatisPagingItemReader) |
| 데이터 로딩 방식 | Mybatis의 resultHandler 또는 cursor 기능으로 쿼리 결과를 한 건씩 스트리밍 처리. 쿼리는 한 번 실행. | OFFSET과 LIMIT 등을 활용하여 페이지 단위로 쿼리를 여러 번 실행하여 데이터를 가져옴. |
| 메모리 사용 | 한 번에 한 건만 처리하므로 매우 효율적 (특히 초거대 데이터셋에 유리). | 페이지 단위로 데이터를 메모리에 올리므로, 페이지 크기에 따라 메모리 사용량 증가. |
| 트랜잭션/DB 연결 | 쿼리 결과를 모두 읽을 때까지 DB 연결과 트랜잭션을 계속 유지. | 각 페이지 쿼리 실행 시에만 짧은 트랜잭션을 사용하며, 필요한 시점에 DB 연결을 맺고 끊을 수 있음. |
| 데이터 정합성 | 쿼리 실행 시점의 스냅샷을 기반으로 하므로, 작업 도중 데이터 변경에도 높은 일관성 유지. 데이터 중복/누락 위험 적음. | 페이지가 넘어갈 때마다 쿼리가 재실행되므로, 작업 도중 데이터 추가/삭제 시 중복되거나 누락될 가능성 있음. |
| 적합한 상황 | - 데이터 정합성이 매우 중요하고, DB 연결을 오래 유지해도 괜찮을 때 - 메모리 부족이 우려되는 초대용량 데이터 처리 시 |
- 대부분의 배치 작업 (더 일반적) - 짧은 트랜잭션으로 DB 부하를 분산해야 할 때 - 재시작 안정성을 확보하고 싶을 때 |
ItemReader 빈 작성
우리는 MyBatis를 이용하고 있으므로 MyBatisCursorItemReader를 이용해서 ItemReader를 작성해보자.
@Bean
@StepScope
MyBatisCursorItemReader<Payment> paymentReader(
@Qualifier("sakilaSqlSessionFactory") SqlSessionFactory sqlSessionFactory,
@Value("#{jobParameters['yearMonth']}") String yearMonth) {
return new MyBatisCursorItemReaderBuilder<Payment>()
.sqlSessionFactory(sqlSessionFactory)
.queryId("com.quietjun.batch.model.mapper.SakilaMapper.selectMonthlyPayments")
.parameterValues(Map.of("yearMonth", yearMonth))
.build();
}
@StepScope와 SPEL
@StepScope는 지연 바인딩(Late Binding)을 위한 annotation으로 해당 빈이 존재하는 scope(ex: singleton, prototype, ...)를 step으로 지정하는 애너테이션이다. 즉 Step 마다 새로 만들어야 함을 의미한다.
이 빈은 Job이 실행되면서 전달되는 JobParameters에서 yearMonth를 사용해야 하는데
- 만약 @StepScope가 없다면 애플리케이션 구동 시 singleton으로 paymentReader 빈이 만들어지고 아직 JobParmaeters가 없기 때문에 yearMonth를 전달받지 못한다.
- @StepScope는 지연 바인딩을 일으켜 애플리케이션이 시작될 때는 paymentReader에 대한 Proxy만 생성하고 나중에 Step 이 실행되면서 JobParameters를 받을 수 있을 때 실제 빈 객체가 생성된다.
StepScope의 빈은 자연스럽게 StepExecutionContext의 내용에 접근할 수 있는데 StepExecutionContext는 JobParameters에 접근할 수 있다. 이 정보에 쉽게 문자열 형태로 접근하기 위해 SPEL(Spring Expression Language)을 사용한다.
@Value("#{jobParameters['yearMonth']}") String yearMonthSPEL을 통해 접근할 수 있는 속성과 대상은 다음과 같다.
- jobParameters: 입력값
- stepExecutionContext: Step 별 저장소 (Map)
- jobExecutionContext: Job 전체 저장소 (Map)
- stepExecution: Step 상태 객체 (통계 + 저장소)
- jobExecution: Job 상태 객체
ItemProcessor
기본
ItemProcessor는 ItemReader에서 read()를 통해 반환된 Item을 ItemWriter로 넘겨주기 전에 변환하기 위한 로직은 갖는 빈이다. 물론 간단한 변환의 경우 ItemReader/ItemWriter에 변환 로직을 넣을 수 있지만 읽기/쓰기와 변환이 혼재되면 재사용이 어렵기 때문에 분리해서 사용하는 것이 권장된다.
@FunctionalInterface
public interface ItemProcessor<I, O> {
@Nullable O process(I item) throws Exception;
}
ItemProcessor 빈 작성
다음은 ItemProcessor의 예이다. source에서 조회된 Payment에 backupdate와 yearmonth 속성을 설정하는 변환을 가한다. 여기서도 jobParameters를 사용하기 위해 @StepScope를 적용했다.
@Bean
@StepScope
ItemProcessor<Payment, Payment> paymentProcessor(
@Value("#{jobParameters['yearMonth']}") String yearMonth) {
return payment -> {
// 이럴일은 없지만 혹시 null인 경우 처리
if (payment.getPaymentId() ==null) {
return null; // Writer로 전달 안 됨
}
// 백업 시점 기록
payment.setBackupDate(LocalDateTime.now());
// 년월 정보 추가
payment.setPaymentYm(yearMonth);
return payment;
};
}만약 ItemProcessor에서 null이 반환되는 경우는 writer로 전달되지 않는다. 불필요한 데이터를 filtering 할 때 null을 반환해주자.
ItemWriter
기본
ItemWriter는 ItemReader의 반대말이다. 따라서 flat file, xml, database 등 다양한 소스를 대상으로 데이터 쓰기를 지원한다.
@FunctionalInterface
public interface ItemWriter<T> {
void write(Chunk<? extends T> chunk) throws Exception;
}ItemWrite는 Chunk 단위로 한방에 커밋이 발생한다. 즉 한 Chunk 안에 있는 모든 데이터가 성공적으로 처리돼야 한 번에 DB에 커밋되고 하나라도 문제가 발생하면 해당 Chunk의 데이터는 모두 롤백 된다.
Chunk의 크기는 성능과도 연결되는데 너무 작으면 I/O 작업이 많아져서 오버헤드가 발생한다. 반면 너무 커지면 적재에 대한 비용이 발생하며 실패 시 부담이 커진다. Chunk의 크기는 Step에서 지정한다.
일반적으로 사용되는 데이터베이스 기반의 writer는 다음과 같이 정리해볼 수 있다.
- JDBC 기반: JdbcBatchItemWriter
- JPA 기반: JpaItemWriter
- MyBatis 기반: MyBatisBatchItemWriter
이 외에도 다양한 ItemWriter가 제공되고 있다.
ItemWriter 구현
다음은 MyBatisBatchItemWriter를 사용하는 예이다.
코드는 특별한 부분이 없고 ItemReader와 달리 @StepScope가 없는 것을 확인할 수 있다. 이 ItemWriter는 Job에서 추가적인 정보를 받을 필요가 없기 때문에 애플리케이션 시작 시점에 빈을 singleton 타입으로 만들면 되기 때문이다.
@Bean
MyBatisBatchItemWriter<Payment> paymentWriter(
@Qualifier("quietjunSqlSessionFactory") SqlSessionFactory sqlSessionFactory) {
return new MyBatisBatchItemWriterBuilder<Payment>()
.sqlSessionFactory(sqlSessionFactory)
.statementId("com.quietjun.batch.model.mapper.QuietjunMapper.insertPaymentBackup")
.build();
}
Step 구성
기본
Step은 앞서 살펴봤듯이 Job 내부의 독립적이고 순차적인 처리 단계로 앞서 작성한 ItemReader, ItemProcessor, ItemWriter로 구성된다. 다음의 예는 Chunk_Size=2인 상태에서 Step의 동작 과정을 보여준다. 아이템이 많다면 read ~ write 과정이 반복된다고 보면 된다.
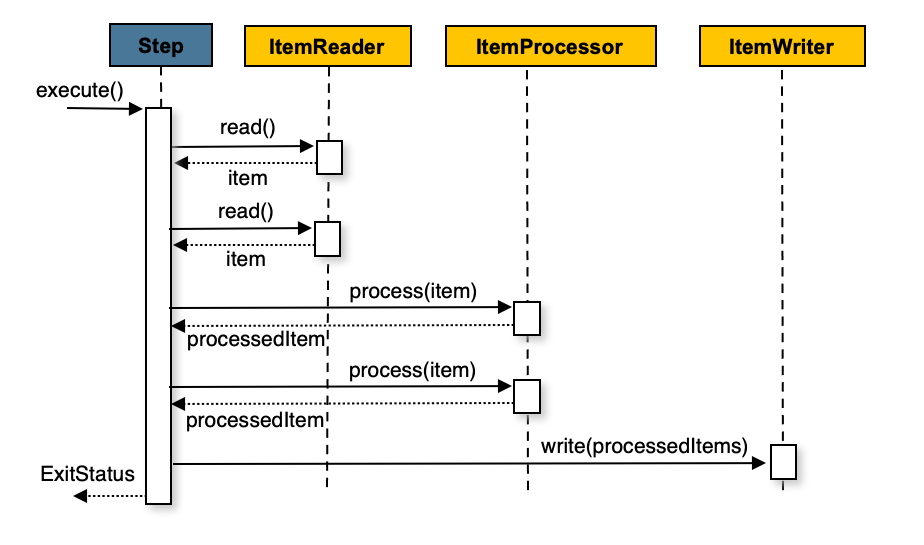
Step을 생성할 때는 StepBuilder를 이용해서 필요한 요소들은 넣어주면 되기 때문에 특별한 어려움은 없다.
ItemReader등을 만들 때 @StepScope를 썻던 것 처럼 Step을 만들 때 @JobScope를 사용할 수 있는데 이 애너테이션 역시 late binding을 위한 것이다. 만약 Step에서 JobParameters를 사용할 예정이라면 필요하지만 그렇지 않다면 불필요하다.
Step 구현
private static final int CHUNK_SIZE = 100;
@Bean
Step backupPaymentStep(
JobRepository jobRepository,
@Qualifier("quietjunTransactionManager") PlatformTransactionManager transactionManager,
MyBatisCursorItemReader<Payment> reader,
ItemProcessor<Payment, Payment> processor,
MyBatisBatchItemWriter<Payment> writer) {
return new StepBuilder("backupPaymentStep", jobRepository)
.<Payment, Payment>chunk(CHUNK_SIZE)
.transactionManager(transactionManager)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
'Spring Batch' 카테고리의 다른 글
| 07. Backup Batch - 3 (0) | 2026.01.07 |
|---|---|
| 06. Backup Batch - 2 (0) | 2026.01.06 |
| 04. Project 구성 (1) | 2026.01.04 |
| 03. SpringBatch 핵심 개념 (0) | 2026.01.03 |
| 02. Spring Batch 계층 구조 (0) | 2026.01.02 |
Contents
소중한 공감 감사합니다