DB/일반
window function 2
- -
이번 시간에는 DBMS의 window function의 over 절에 대해서 살펴보자.
over 절의 활용
over() 절
window 함수를 사용하기 위해서는 over() 절이 필수 항목이다. sum()을 그냥 쓰면 집계함수가 되고 over()가 있어야 window 함수가 된다. 다음의 간단한 예를 살펴보자.
select title, length, rating,
sum(length) over() "길이합",
sum(length) over(partition by rating) "등급별 길이합"
from film
order by length;
첫 번째 경우 처럼 over 절이 비어있으면 모든 쿼리 행을 대상으로 구성되며 window 함수는 전체 쿼리 결과를 하나의 파티션으로 취급한다. 따라서 조회된 모든 데이터에서 합계를 계산한다.
두 번째의 경우는 partition by rating에 의해 window 함수는 파티션(rating) 별 sum을 구한다. 값으로는 마치 집계함수로 썼을 때의 group by와 유사하다고 보면 된다. 하지만 결과는 partition 별로 각 row에서 사용된다.
over 절의 구성
over 절은 window 함수가 어떻게 쿼리 행을 처리할 것인지를 결정한다. over 절은 다음과 같이 구성될 수 있다.
over_clause:
{OVER (window_spec) | OVER window_name}- window_spec : 직접 spec을 정의한다.
- window_name : 별도의 window 절에 spec을 정의하고 이름 기반으로 window를 참조한다.
window_name은 쿼리 내의 다른 부분에 window 절을 이용해서 구성한 내용을 이름 기반으로 참조할 때 사용할 수 있으며 뒤에 나오는 partition, order, frame 절은 기존의 window의 속성을 재지정할 수 있다.
SELECT
val,
ROW_NUMBER() OVER (ORDER BY val) AS 'rn',
RANK() OVER (ORDER BY val) AS 'ra',
DENSE_RANK() OVER (ORDER BY val) AS 'dr'
FROM numbers;SELECT
val,
ROW_NUMBER() OVER w AS 'row_number',
RANK() OVER w AS 'rank',
DENSE_RANK() OVER w AS 'dense_rank'
FROM numbers
WINDOW w AS (ORDER BY val);위의 코드에서 좌측은 여러 window 함수에서 (ORDER BY val)이 반복된다. 이 부분을 오른쪽 코드처럼 WINDOW w를 미리 정의해두고 window 함수에서 OVER w 형태로 참조할 수 있다. WINDOW를 정의하는 방법은 아래의 window_spec를 참조하면 된다.
다음은 window_spec을 직접 구성하는 예이다.
window_spec:
[window_name] [partition_clause] [order_clause] [frame_clause]window_spec은 항목별로 예제와 함께 살펴보자.
window_spec의 구성
partition_clause
partition_clause은 쿼리 행을 그룹으로 나누는 방법으로 지정된 행에 대한 window 함수의 결과는 해당 행이 포함된 파티션의 행을 기반으로 한다. 생략 시 전체 쿼리 행을 하나의 파티션으로 본다.
partition_clause:
PARTITION BY expr [, expr] ...first_value에서 partition 설정을 해보자.
FIRST_VALUE(expr) [null_treatment] over_clausefirst_value는 partition에서 expr에 해당하는 첫 번째 값을 반환한다.
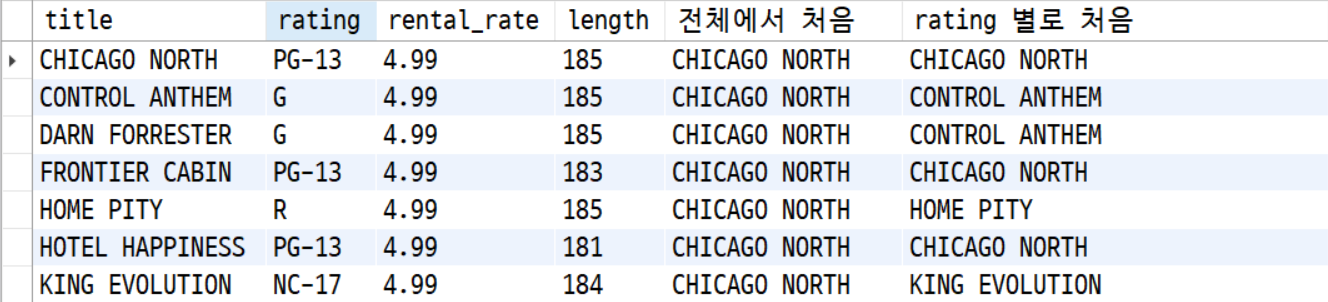
select title, rating, rental_rate , length,
first_value(title) over() "전체에서 처음",
first_value(title) over(partition by rating) "rating 별로 처음"
from film
where length > 180 and rental_rate>3;실행 결과는 다음과 같다.
order_clause
order_clause는 각 파티션에서 행을 정렬하는 방법을 나타내며 ASC | DESC를 가질 수 있고 기본은 ASC이다. 일반 쿼리에서의 order by와 헷갈릴 수 있는데 일반 쿼리의 order by는 정렬해서 보여주는 용도이고 window 함수의 order by는 정렬해서 데이터를 처리하기 위함이다. 예를 들어 rank를 정하거나 누적합을 처리할 때 사용된다.
order_clause:
ORDER BY expr [ASC|DESC] [, expr [ASC|DESC]] ...여기서는 rank 계열의 함수들을 써보자. 비슷한 녀석들이 여럿 있다.
RANK() over_clause
DENSE_RANK() over_clause
PERCENT_RANK() over_clause이 함수들은 over 절의 order by에 의해 등수를 매기는데 order by를 생략하면 모드를 동일한 피어 (동일한 순위의 요소들) 로 본다.
RANK()의 경우는 피어들에 동일한 순위 값을 할당하고 그 다음으로 큰 값은 개수 기반으로 등수를 정한다.(1,1,1,4,...) DENSE_RANK() 역시 피어에 동일한 순위 값을 할당하지만 다음으로 큰 값은 단지 +1이다.(1, 1, 2) PRECENT_RANK()는 백분율로 등수를 나타낸다.
누가누가 긴 영화를 만들었는가 페스티벌을 진행할 예정이다. rank, dense_rank, percent_rank를 이용해서 순위를 매겨보자.
SELECT
title, rating, length,
RANK() OVER (ORDER BY LENGTH desc ) AS "rank", # 내림차순
DENSE_RANK() OVER (ORDER BY length) AS "dense_rank",
PERCENT_RANK() OVER (ORDER BY LENGTH) * 100 AS "percent_rank"
FROM film where rating ='R' order by length desc ;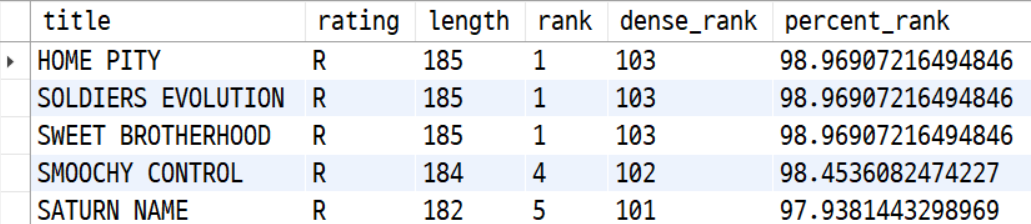
아주 편리하게 'CHICAGO NORTH'가 1위를 차지한 것을 알 수 있다.
frame_clause
frame이란?
frame이란 현재 파티션의 하위 집합으로 window 함수가 데이터를 처리할 때 실제로 사용할 행의 범위를 정의하는 것이다. window의 실질적인 크기라고 볼 수 있다. frame 설정은 window 함수를 정의할 때 over 절 안에서 하는데 명시적으로 지정하지 않으면 기본 frame이 사용된다.
기본 frame은 order by 절이 포함되어있는지 여부에 따라 달라진다.
- order by가 있는 경우: RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW가 적용된다. 즉 처음부터 현재까지의 행이 대상이다.
- order by가 없는 경우: RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING이 적용된다. 즉 처음부터 마지막까지의 모든 행이 대상이다.
SELECT
payment_id, payment_date, customer_id, amount,
SUM(amount) OVER () AS '총 결재 비용',
SUM(amount) OVER (ORDER BY payment_date) AS '결재일까지 누적 결재 비용'
FROM
payment
where customer_id=130;
frame 조정
필요에 따라 frame을 조정하여 특정 범위만 포함하거나 제외할 수도 있다. 만약 현재 건과 다음 건만을 대상으로 하고 싶다면 다음과 같이 작성할 수 있다.
SELECT
payment_id, payment_date, customer_id, amount,
SUM(amount) OVER (ORDER BY payment_date rows between 1 preceding and 1 following)
AS '주변 3일 누적 비용'
FROM
payment
where customer_id=140;
범위 지정을 위해 사용되는 키워드는 다음과 같다.
- RANGE 는 BETWEEN 과 항상 함께 사용되며, 특정 프레임을 지정할 수 있다.
- ROWS 는 기본적으로 현재 행을 기준으로 시작지점을 지정할 수 있지만(ex: rows 2 preceding), BETWEEN 을 사용하게 되면 RANGE와 같은 효과를 낸다.
- UNBOUNDED PRECEDING: 현재 행에서 시작까지 범위 설정
- N PRECEDING: 현재 행에서 N 개 이전 행까지의 범위 설정(N은 정수)
- CURRENT ROW: 현재 행을 포함
- N FOLLOWING: 현재 행에서 N 개 이후 행까지의 범위 설정
- UNBOUNDED FOLLOWING: 현재 행부터 마지막 행까지의 범위 설정
고객의 최초 대여일 기억해주고 최종 대여일 파악해서 대여 유도하기
고객의 렌탈 목록에 최초 대여일과 마지막 대여일을 포함시켜서 반갑게 맞아주면서 다음 대여를 유도해보자.
SELECT
c.email, rental_date, f.title,
FIRST_VALUE(rental_date) OVER (PARTITION BY customer_id ORDER BY rental_date)
AS `최초 대여일`,
LAST_VALUE(rental_date) OVER (PARTITION BY customer_id ORDER BY rental_date
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS `최종 대여일`
FROM
rental r join customer c using(customer_id)
join inventory i using(inventory_id)
join film f using(film_id)
ORDER BY
customer_id, rental_date;
'DB > 일반' 카테고리의 다른 글
| [transaction]select for share, select for update (0) | 2025.03.13 |
|---|---|
| window function 1 (0) | 2024.09.09 |
| [H2] Spring Boot에서의 테스트를 위한 DB 설정 (0) | 2023.10.23 |
| [index] index 성능 확인 (0) | 2023.10.12 |
| [Transaction] 02. Transaction Isolation Level (0) | 2023.10.11 |
Contents
소중한 공감 감사합니다