알고리즘/기본코드
LinkedList vs ArrayList
- -
LinkedList vs ArrayList
Java에서 순서 있는 목록을 관리하는 인터페이스는 java.util.List 인터페이스이다.
List의 특징은 순서가 있는 데이터의 집합으로 순서가 있기 때문에 데이터의 중복이 허용된다.

List는 인터페이스이기 때문에 직접 객체를 생성할 수 없고 구현체 class가 필요하다. 이 구현체의 가장 대표적인 클래스가 java.util.ArrayList와 java.util.LinkedList이다.
먼저 각각의 특성에 대해 살펴보자.
ArrayList
ArrayList는 배열에서 출발한 List
ArrayList는 이름에서 풍기듯이 내부적으로 배열을 만들고 데이터를 관리한다.
transient Object[] elementData; // non-private to simplify nested class access
배열의 특징은 무엇인가? 동일한 데이터 타입을 저장하며 연속된 메모리를 사용해야 하기 때문에 한번 크기가 정해지면 그 크기를 변경할 수 없다. 하지만 데이터들이 연속적으로 배치되어있어서 순차적인 사용 시 엄청난 성능을 보여준다.
ArrayList는 배열의 이런 특징을 그대로 가져간다.
동일 데이터 타입 관리
다른 Collection API들 처럼 ArrayList도 Object 타입으로 데이터를 관리한다. 물론 Generic을 이용해서 저장할 타입을 한정 지을 수 있다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{ ... }
고정된 크기
ArrayList를 사용하면서 많이 헤깔리는 부분인데 ArrayList는 한번 크기가 정해지면 변경할 수 없다. ArrayList는 add를 이용해서 데이터를 넣으면 넣는 족족 다 들어가던데 아닌가?
ArrayList는 데이터가 계속 추가되서 기존의 ArrayList로를 수용할 수 없을 때 보다 큰 배열을 만들고 데이터를 이전시킨다. 물론 이 과정에서 큰 비용이 발생한다.
다음은 ArrayList의 add 메서드를 쫒아가다 보면 만날 수 있는 grow 메서드이다.
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}대충 코드를 보면 보다 더 큰 크기(newCapacity)의 배열에 기존 배열(elementData)를 복사해 넣는 것을 볼 수 있다. 내부적으로 배열이니까 크기를 늘일 수 있는 유일한 방법은 보다 큰 배열을 새로 만드는 것 뿐이다.
데이터 추가/삭제와 인덱스 관리
ArrayList를 사용하다가 중간에 데이터를 넣거나 중간에서 삭제하다 보면 인덱스가 자동으로 조정되는 것을 볼 수 있다. 이 과정에서도 마법은 일어나지 않는다. 중간에 데이터를 넣거나 삭제하기 위해서는 그 뒤에 있는 나머지 요소들의 인덱스가 모조리 한 칸씩 당겨지거나 한 칸씩 뒤로 밀려나게 된다. 역시 배열과 동일하다.
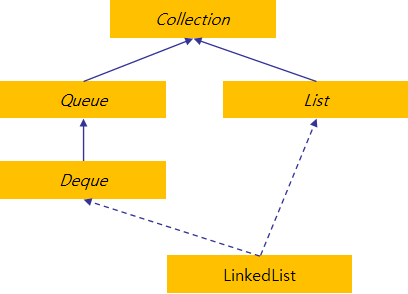
LinkedList
화려한 부모
LinkedList는 List는 물론 Queue interface 까지 구현하고 있어서 ArrayList보다 활용도가 더 많다고 볼 수 있다.
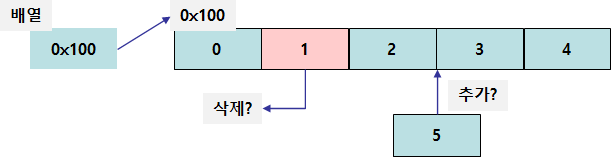
연결된 Node를 이용한 데이터 관리
반면 LinkedList는 배열을 기반으로 하지 않고 연결된 노드(Node)의 개념을 이용해서 데이터를 관리한다. 각 노드는 데이터와 함께 다음 노드에 대한 참조 값을 갖는다.

위 그림처럼 각 노드가 다음 노드의 참조 값을 가지고 있기 때문에 메모리에 연속적으로 구성될 필요가 없게된다. 연속적으로 구성될 필요가 없기 때문에 크기를 한정 지을 필요도 없고 데이터가 추가될 때 배열을 새로 만드는 등의 행위가 불필요 하다.
다만 이에 대한 반대 급부로 데이터를 찾아가는데 매번 주소를 확인해야 하기 때문에 속도적으로 느릴 수밖에 없다.
데이터 추가/삭제와 인덱스 관리
ArrayList는 중간에 데이터를 넣거나 뺄 때 뒤쪽 요소들의 인덱스가 모조리 조절되어야 하기 때문에 성능상 좋지 않다. 하지만 LinkedList의 경우는 단지 다음 요소에 대한 참조 값만 변경해주면 끝나기 때문에 단 두 번의 연산만으로 처리가 끝난다.

When to use what?
성능 비교
앞서 이야기 했듯이 ArrayList와 LinkedList의 가장 큰 차이는 데이터의 관리를 배열로 할 것인가? 연결 노드로 할 것인가이고 이에 따라 순적적 접근과 비 순차적 접근에서 극명하게 성능 차이를 보인다.
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class ArrayVsLinkedTest {
private static void addTest(String testcase, List<Object> list) {
long start = System.nanoTime();
for (int i = 0; i < 1000000; i++) {
list.add(new String("Hello"));
}
long end = System.nanoTime();
System.out.println(testcase + " 소요시간 : " + (end - start));
}
private static void addTest2(String testcase, List<Object> list) {
long start = System.nanoTime();
for (int i = 0; i < 100000; i++) {
list.add(0, new String("Hello"));
}
long end = System.nanoTime();
System.out.println(testcase + " 소요시간 : " + (end - start));
}
private static void accessTest(String testcase, List<Object> list) {
long start = System.nanoTime();
for (int i = 0; i < 100000; i++) {
list.get(i);
}
long end = System.nanoTime();
System.out.println(testcase + " 소요시간 : " + (end - start));
}
public static void main(String[] args) {
ArrayList<Object> alist = new ArrayList<Object>();
LinkedList<Object> llist = new LinkedList<Object>();
addTest("순차적 추가: ArrayList", alist);
addTest("순차적 추가: LinkedList", llist);
addTest2("중간에 추가: ArrayList", alist);
addTest2("중간에 추가: LinkedList", llist);
accessTest("데이터 접근: ArrayList", alist);
accessTest("데이터 접근: LinkedList", llist);
}
}
| 구분 | 순차 추가/수정/삭제 100만건 처리 기준 |
비 순차 추가/수정/삭제 10만건 처리 기준 |
조회 10만건 조회 시 |
| ArrayList | 22,108,711 | 31,444,190,835 | 6,428,554 |
| LinkedList | 85,540,898 | 5,900,334 | 20,895,705,164 |
(단위: 나노초)
간단히 테스트 해본 결과로는 C/U/D과정에서 순차적인 처리에서는 ArrayList가 비 순차적 처리에서는 LinkedList가 우수한 것을 볼 수 있다. 하지만 조회의 경우에서는 ArrayList가 월등한 성능을 보여준다.
결론
ArrayList냐 LinkedList냐는 당연히 어떤 클래스가 좋고 어떤 클래스가 나뿌다라는 이야기가 아니라 용도에 적합하게 사용해야 한다는 점이 중요하다.
-
소량의 데이터를 가지고 사용할 때는 사실 큰 차이가 없다.
-
정적인 데이터를 활용하면서 조회하는 경우는 ArrayList가 유리하다.
-
동적으로 추가/수정/삭제가 많은 작업에는 LinkedList가 유리하다.
실전 적용
둘의 차이점을 잘 이해했다면 다음 문제를 풀어보면서 어떤 라이브러리를 사용하는 것인 유리한지 고민해보자.
https://www.acmicpc.net/problem/1158
1158번: 요세푸스 문제
첫째 줄에 N과 K가 빈 칸을 사이에 두고 순서대로 주어진다. (1 ≤ K ≤ N ≤ 5,000)
www.acmicpc.net
https://www.acmicpc.net/problem/1168
1168번: 요세푸스 문제 2
첫째 줄에 N과 K가 빈 칸을 사이에 두고 순서대로 주어진다. (1 ≤ K ≤ N ≤ 100,000)
www.acmicpc.net
'알고리즘 > 기본코드' 카테고리의 다른 글
| [입출력]01. Scanner (0) | 2024.11.27 |
|---|---|
| Union-Find 연산의 성능 개선 (0) | 2020.10.10 |
| 문자열 패턴 매칭 3 - KMP (0) | 2020.02.28 |
| 문자열 패턴 매칭 2 - Rabin Karp (0) | 2020.02.28 |
| 문자열 패턴 매칭 1 - Brute Force (0) | 2020.02.28 |
Contents
소중한 공감 감사합니다